




Künstliche Intelligenzen (KI) sind in unserer spannenden Zeit der Renner in der Tech-Welt: Man setzt riesige Hoffnungen darauf und fürchtet gleichzeitig die „Macht der Maschinen“. Ich verfolge lose die Berichterstattung und es wurde jetzt mal Zeit für einen größeren Beitrag über dieses weite Feld. Denn wie sich herausstellt, sind KIs alles andere als unfehlbar – immer wieder kommt es zu ungewollter Diskriminierung und die Automatisierung geht zu weit. Schuld sind: Die Menschen!
[toc]
KI – Segen oder Untergang?
Letzteres ist ja nichts Neues. Die Terminator-Filmreihe und die Matrix-Trilogie sind nur zwei sehr populäre Beispiele für ein Szenario, in dem „die Maschinen“ die Menschheit an den Rande der Ausrottung bringen. Deutlich älter sind etwa auch Isaac Asimovs berühmte „Gesetze der Robotik„, also eine Programmierung, die Roboter davon abhalten sollen, Menschen Schaden zuzufügen.
KI als Gegenstand zahlreicher Apokalypse-Szenarien
Die Furcht – oder sagen wir besser: der Respekt vor der KI ist auch nicht ganz unbegründet. Mit all unseren Fehlern sind wir Menschen zwar die Schöpfer aller künstlichen Intelligenzen, aber unsere Schöpfung ist uns in vieler Hinsicht überlegen. Etwa in Bezug auf Geschwindigkeit und Logik. 1996 schlug der IBM-Schachcomputer Deep Blue erstmals einen amtierenden Weltmeister.
Und dabei war Deep Blue nicht mal eine wirkliche KI, sondern eben ein Computer, der nur eines konnte: Schach spielen. Er kannte die Regeln des Spiels, hatte alle Strategien und Züge wichtiger Weltmeisterschaften im Speicher und konnte extrem schnell extrem viele Züge im Voraus berechnen. Und damit war er seinem „langsamen“ menschlichem Kontrahenten gegenüber im Vorteil. Mehr konnte das Ding überhaupt nicht. Kein Bewusstsein, kein selbstständiges Lernen und natürlich keine Empathie.
KI als Garant für Effizienz
Und bei eben diesem selbstständigen Lernen sind wir jetzt angelangt. Es gibt zahlreiche Projekte, die verschiedenen KIs beibringen wollen, wie sie sich selbst alles beibringen. Das spart uns Arbeit – und wir können ja schließlich nicht für alles Regeln einprogrammieren. Wäre doch viel praktischer, wenn sich eine KI selbst an neue Begebenheiten anpasst und klug darauf reagiert.
Was man damit alles machen könnte! Reporter-KIs, die selbstständig das Netz nach neuen Pressemeldungen absucht und in Sekundenbruchteilen schöne Reportagen dazu schreibt. Chirurgen-KIs, die eine Operation zitterfrei durchführen können und niemals müde sind – und durch zahlreiche Simulationen auch auf Komplikationen reagieren könnte. Busfahrer-KIs, Call-Center-KIs, Aktienbroker-KIs und Berater-KIs, die auf alle möglichen Situationen reagieren und sie irgendwann deutlich besser meistern als gelernte Fachkräfte. Und außerdem sind sie viel billiger. Die Chancen und Risiken der Digitalisierung der Arbeitswelt ist deswegen ein heißes Eisen!
Aber naja, das sprengt jetzt den Rahmen – es gäbe soviel Interessantes zu sagen und zu diskutieren. Kommen wir zurück zum Thema: Selbstständiges Lernen.
Die Datenbasis ist das A und O!
Lernen funktioniert bei künstlichen Intelligenzen genau wie beim Menschen: Durch ständiges Wiederholen und Erfahrung. Lass eine KI 20.000 Katzenbildern anschauen und sage ihr: Jedes Bild zeigt eine Katze. Dann wird sie zuverlässig bis in alle Ewigkeit Katzen in jeder möglichen Pose identifizieren können.

Auf diese Weise sollen KIs möglichst viele Bildmotive erkennen und mit entsprechenden Schlagwörtern versehen – und Bilderkennung ist ein riesiges Feld in der heutigen Zeit, in der es mehr Fotos und Videos gibt als jemals zuvor. Menschen können gar nicht sichten, was tagtäglich so durchs Netz wandert oder von Kameras aufgenommen wird. Deswegen ist es kein Wunder, dass beispielsweise auch Google ganz vorne in der Bilderkennung mitspielt.
Bilderkennung mit Google Lens
Google Lens ist eine Anwendung, die du als separate App aufs Smartphone laden kannst oder über den Google Assistant öffnest. Ziel von Google Lens ist es, dem Nutzer mit der Bilderkennung zu helfen. Dazu nutzt die Anwendung das live-Bild der internen Kamera, sie kann aber auch mit bereits gespeicherten Bildern in der Galerie arbeiten. Google wirbt damit, dass Lens etwa die Kontaktdaten auf einer fotografierten Visitenkarte direkt als Kontakt im Handy anlegen kann oder geknipste Gegenstände identifiziert und Informationen dazu liefert.
Ich bin mal mit Google Lens durch die Wohnung gewandert und habe Kalenderbilder, Poster und Fotos in Magazinen anvisiert, um zu schauen, was Google Lens mir liefert. Und das war verblüffend beeindruckend! Bei Produktverpackungen, z.B. einer Dose Katzenfutter, lag Google Lens niemals daneben – ist aber auch eine einfache Übung. Es erkannte das Produkt und man kann dann direkt danach suchen, zB. für einen Preisvergleich.
Schwieriger wurde es aber dann mit Bildern, die keine schriftlichen Infos mitliefern – und trotzdem kam Google Lens gut zurecht! Hier ein paar Beispiele:
- Poster von einer Rekonstruktion der antiken Stadt Pergamon (zu sehen im Pergamonmuseum in Berlin): Google erkannte den Pergamonaltar und lieferte auch folgerichtig das Pergamonmuseum als Ergebnis. Kein Wunder, es gibt Tausende Bilder des Pergamonaltars im Internet, und das Bauwerk sieht heute kaum anders aus als damals (und damit in der Rekonstruktion)
- Ansicht einer Stadt in Portugal in einer Zeitschrift: Google Lens erkannte die Stadt. Aber auch kein Wunder, auch davon dürfte es eine große Datenbasis geben.
- Poster von einer Rekonstruktion des antiken Roms: Das ist schon schwieriger, weil es hier keine Gebäude drauf zu sehen gibt, die so noch existieren. Aber Google erkannte die Rekonstruktion trotzdem und lieferte als Ergebnis den Ort, an dem die Rekonstruktion präsentiert wurde. Dort habe ich das Poster auch gekauft :D
- Und der richtige Wow-Effekt: Ein Kalenderfoto, das die Landschaft der Isle of Skye in Schottland zeigt. Und genau die hat Google Lens erkannt, obwohl die Perspektive anders ist! Der Text zum Bild war übrigens abgedeckt, Google hatte keine Hilfe :D
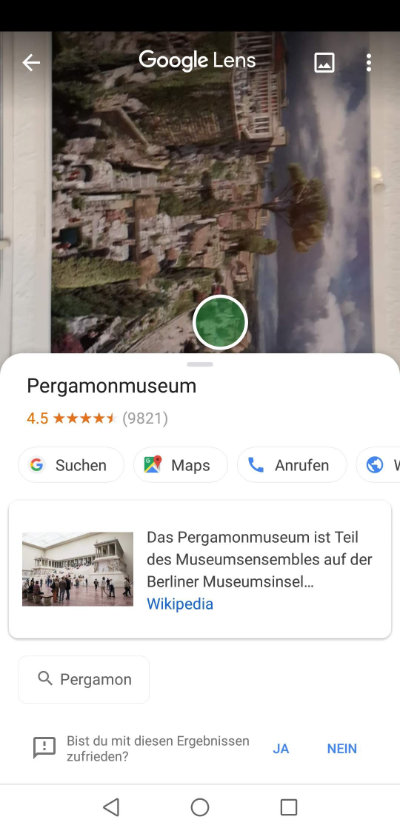
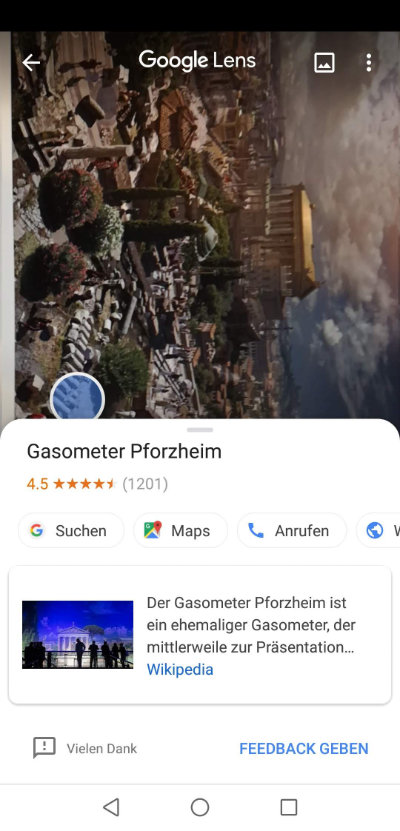
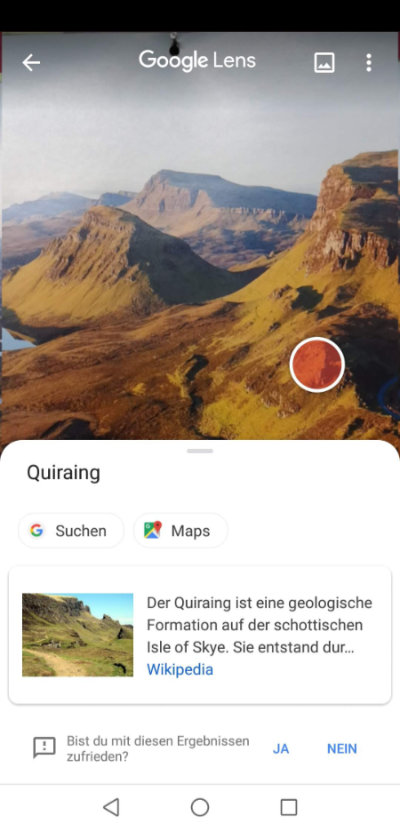
Google greift eben auf ein riesiges Arsenal an bereits vorhandenen Bildern und Daten zurück und kann so analysierte Fotos einem Kontext zuordnen. Da ist Google natürlich der Platzhirsch.
Du merkst es also schon: Alles hängt von den eingefütterten Informationen ab, also der Datenbasis. Wer eine KI nun zielgerichtet trainieren möchte, damit sie nicht nur oberflächlich analysieren kann, sondern auch in die Tiefe geht, der muss sie ihr genauere Daten vorgeben. Zeigst du der KI nur Fotos von Norwegischen Waldkatzen, wird sie eine nackte Stummelschwanzkatze nur sehr unsicher als „Katze“ identifizieren.
Und genau da liegen auch sehr oft die Probleme, mit denen sich KI-Forscher heute konfrontiert sehen: KIs unterliegen häufig unbewussten und ungewollten Vorurteilen.

Wann ist eine Braut eine Braut?
In einem Fall zeigt sich das daran, dass eine KI Bräute auf Bildern taggen, also kennzeichnen soll. Das funktioniert sehr gut, wenn die Braut ein weißes Kleid und einen Schleier trägt. Das verstehen wir unter Bräuten. In Indien sehen Bräute aber anders aus. Ein Inder würde eine indische Braut sofort erkennen, aber die KI sieht nur „Person, Leute“ auf einem Foto mit einem indischen Brautpaar.
Während also westliche Bilder korrekt kategorisiert werden können, fällt die Verschlagwortung östlicher Bilder deutlich schmaler aus. Stellen wir uns nun vor, die KI soll nach ihrer Bildersichtung eine Statistik über Hochzeiten erstellen – sie käme zu dem Ergebnis, dass im Westen viel öfters geheiratet wird. Wer nun die Grundlage dieser Statistik nicht überprüft, sondern nur die Aussage sieht, der sitzt falschen Infos auf.
Vorurteil: Investoren sind natürlich männlich!
In einem anderen Beispiel geht es nicht um Bilder, sondern um Text. Google entwickelt eine KI namens Smart Compose, die in GMail ganze Sätze vorhersagen kann/soll und damit als smarter Assistent gedacht ist, der Zeit sparen kann. Die KI verlässt sich auf eine riesige Datenbasis an Texten, die in eMails üblicherweise geschrieben werden, analysiert den Kontext der Mail und lernt außerdem stetig dazu, wie der eigene „Besitzer“ sich auszudrücken pflegt.
So kann Smart Composer durch nur wenige Wörter oder sogar Buchstaben aus dem Kontext schließen, was der Mensch schreiben will – und schlägt das dann vor. Wenn das funktioniert, spart das natürlich eine Menge Zeit.
Die große Datenbasis bildet natürlich Standards ab, aus denen sich dann Regeln ableiten lassen. Zum Beispiel, dass Menschen, die mit großen Geldmengen hantieren, meistens Männer sind. Wenn (sagen wir) 80% aller Investoren männlich sind, dann ist die Wahrscheinlichkeit groß, dass das auch weiterhin so ist. Klar, verständlich, geht uns Menschen (leider) auch oft so.
Dieser Fall ist auch bekannt geworden: Geht es in einer Mail um einen Investor, dann nutzt Smart Compose in seinen Satzvorschlägen das männliche Personalpronomen. Bedeutet also: Die KI traut statistisch nur dem einem Geschlecht zu, mit größeren Geldmengen umgehen zu können.
Diskriminierung durch historische Daten
Fatal ist sowas dann, wenn man eine KI Entscheidungen treffen lässt. Sie bringt also ihre ganzen statistischen Wahrscheinlichkeiten der Vergangenheit mit und wendet sie auch aktuell an. Stellen wir uns vor, eine KI soll alle Bewerber auf eine Stellenausschreibung im männlich dominierten technischen Bereich prüfen und eine Vorauswahl aller geeigneten Kandidaten treffen. Die KI weiß: In den letzten 10 Jahren wurden mehr Männer eingestellt, also sind Frauen schlechter geeignet. Deswegen ab in die Tonne mit der weiblichen Bewerberin!
Klingt komisch? Ist so passiert, und zwar bei Amazon. Dort hat seit 2014 eine KI Bewerbungen geprüft und alle Bewerbungen nach verschiedenen Kriterien beurteilt. Das manuelle Prüfen von Bewerbungen ist natürlich aufwändig, deswegen freute man sich bei Amazon, dass eine KI das übernommen hat. Am Ende ließ man sich die 5 aussichtsreichen Kandidaten anzeigen und stellte die ein.
Wie die KI die Vorauswahl getroffen hat, und ob das fair war, hat in dem Moment nicht so sehr interessiert. Zeit ist schließlich Geld. Erst später kam heraus, dass die KI weibliche Bewerber grundsätzlich schlechter bewertete. Selbst, wenn das Geschlecht gar nicht aus der Bewerbung hervorging. Dabei reichte ihr die Mitgliedschaft in Frauenvereinen schon aus. Das bedeutet, dass Frauen pauschal schlechtere Chancen im Bewerbungsprozess hatten – und zwar ohne die Chance, ihre zweifellos vorhandene Qualifikation überhaupt einem Menschen darlegen zu können.
Lems Kurzgeschichte sieht es voraus
1966 erschienen die zehn Kurzgeschichten über Pilot Pirx von Stanislaw Lem im polnischen Original. Das lesenswerte Buch erzählt zu einer Zeit, in der man noch mit Lochstreifen-Rechnern arbeitete, Geschichten über Erfahrungen mit Zukunftstechnologien, unter anderem mit „Automaten“ (Lems Begriff für Roboter bzw. KIs).
In einer dieser Geschichten, es müsste „Der Unfall“ sein, stürzt ein vollbesetztes Passagier-Raumschiff während der Landung auf dem Mars ab. Man steht vor einem Rätsel – diese Schiffe sind schon so oft auf dem Mars gelandet, das ist eigentlich alles Routine. Am Ende kommt heraus, dass der verantwortliche Programmierer der KI, die das Raumschiff steuerte, unter Zwangsstörungen litt. Er musste immer wieder überprüfen, ob er den Herd ausgemacht hatte, ob er die Tür abgeschlossen hatte usw. Dieses Verhalten übertrug er unbewusst auf seine KI. Er wies sie an, in schwierigen Situationen ständig alle Daten neu anzufordern und sie zu überprüfen. Am Ende war die KI zu sehr damit beschäftigt, die unnütze Datenflut zu bewältigen, dass sie das Schiff nicht mehr steuern konnte.
Das ist nicht exakt vergleichbar mit Vorurteilen aufgrund der statistischen Datenbasis, zeigt aber das gleiche Problem: Letztlich sind KIs nur so gut wie ihre Schöpfer, also wir Menschen. Unsere Fehler bzw. unsere Perspektiven übertragen sich auf den „Schüler“. In gewissem Sinne verhalten sich KIs also selbst irgendwie menschlich.
Zurück zu Schach und Katzen: Lernen ohne Datenbasis?
In manchen Fällen könnte man die nicht repräsentative Datenbasis auch weglassen. Zum Beispiel beim Schach, da liegt das sogar nahe. Gib der ungelernten KI nur die Regeln und sag ihr: Nutze die Regeln, um am Ende den gegnerischen König Schachmatt zu setzen. Die Regeln sind klar und deutlich, es gibt keine Ausnahmen und nichts, was irgendwie dazwischenfunken könnte. Und dann lass die KI spielen.
Sie entdeckt selbst, wie man im Spiel am besten voran kommt. Während Deep Blue noch auf eingespeicherte Situationen bereits gespielter Spiele zurückgriff, um das Vorgehen zu planen, kennt die KI AlphaZero kein Schäfermatt und keine Rochade, also keine bekannten und bewährten Züge. Sie erschließt sich selbst, was Erfolg haben kann, und spielt so viel dynamischer. So kann sie auch völlig unvorhersagbar reagieren, indem sie Dinge tut, die nie zuvor jemand in der gleichen Situation getan hat.
Auf diese Weise schlägt AlphaZero aktuell alle früheren Schachcomputer mit Leichtigkeit, und das nach nur kürzester Lernzeit und mit weniger Rechenschritten.
Schön – aber dieses selbstständige Lernen durch in Stein gemeißelte Regeln geht nicht immer. Wenn eine KI eine Katze identifizieren soll, dann muss sie genug Katzen gesehen haben. Ansonsten kann sie eben eine Katze nicht mit Sicherheit von einem Luchs oder einem kleinen Hund mit spitzen Ohren unterschieden. Sie stellt dann vielleicht fest: Das fragliche Ding ist mit 70 prozentiger Wahrscheinlichkeit eine Katze. Also ist es eine Katze. Und wenn es dann doch ein Hund ist?
Da sind wir Menschen den KIs mit unserem Abstraktionsvermögen eben doch voraus. Wir brauchen keine 20.000 Katzenbilder, um eine Katze zu erkennen :D
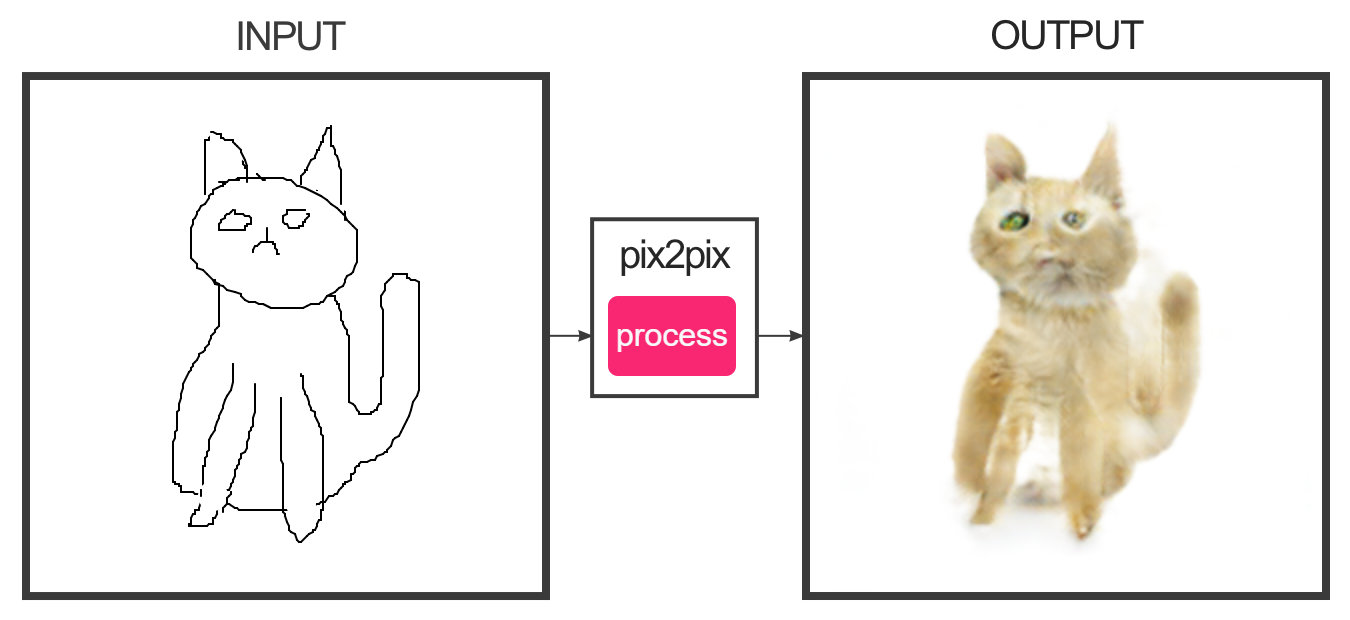
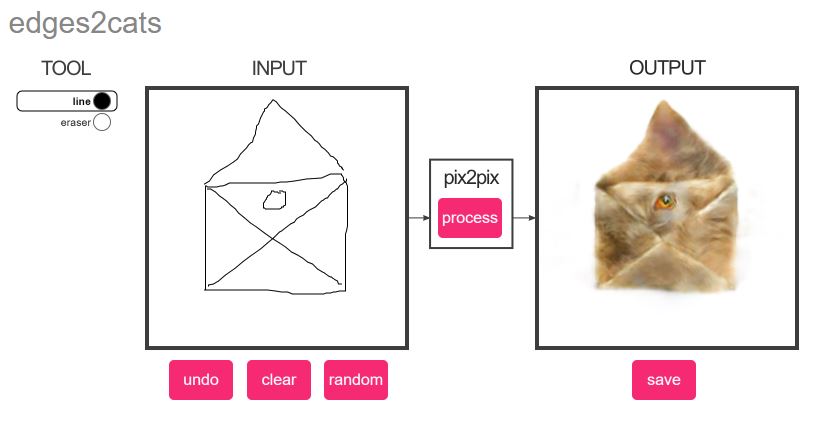
Abstrahieren im Selbstversuch: Edges to Cats
Man kann es aber auch umgekehrt machen. Es gibt eine KI, die 2000 Katzenbilder im Speicher hat und dadurch gelernt hat, wie eine Katze in der Regel aussieht. Katzen haben ein paar markante Formen: Augen, Nase, Beine, Ohren. Legt man der KI nun Skizzen vor, versucht sie, die ihr bekannten Katzenformen in der Skizze zu identifizieren und das Bild mithilfe der Stockfotos zu verfolständigen.
Das kannst du auf der Website edges2cats direkt selbst probieren. Die Ergebnisse sind interessant .. und verstörend (aber was kann die KI dafür, wenn wir sie nur ärgern wollen :D). Probier es mal aus!

Fazit: Interessante Versuche mit optimierbaren Erkenntnissen
Am Ende bleibt nun zu sagen, dass zur Zeit extrem viele Erfahrungen mit KIs in sehr unterschiedlichen Bereichen gesammelt werden. Es ist interessant, KIs mit unvorhergesehenen Situationen zu konfrontieren und zu schauen, wie sie reagiert. Dabei zeigt sich dann, dass die Systeme noch weit davon entfernt sind, perfekt zu sein oder gar wichtige Entscheidungen treffen zu dürfen. KIs sind zwar unbestechlich und frei von Emotionen oder persönlichen Vorlieben, aber, wie wir sehen, nicht frei von Vorurteilen. Da ist noch viel zu tun.
Und insgesamt mag es interessant sein, wenn eine KI das Schreiben von Briefen übernimmt, aber das geht – zumindest im persönlichen Bereich – doch deutlich zu weit. Klar, es spart Zeit, aber letztlich führt das zur Entmündigung des Menschen. Führen wir das Szenario weiter, ist der Schritt zur kompletten Erledigung der Kommunikation nicht weit. Deine Assistenz-KI analysiert dein Verhalten und lernt so deine Vorlieben kennen. Irgendwann antwortet sie ohne deine Aufsicht auf deine Mails – einfach, weil sie das gut kann und es auch ganz in deinem Sinne tut. Der Empfänger, bzw. dessen KI, antwortet dann wieder zurück. Im Grunde kommunizieren die KIs, und am Ende poppt bei dir eine Erinnerung auf, weil die beiden für dich einen Termin gemacht haben.
Yuval Noah Harari schreibt in seinem extrem interessanten Buch Homo Deus auch über die Konsequenzen und sogar Gefahren, wenn der Mensch nicht mehr selbst denken muss, sondern nur das tut, was die KI sagt. Denn tatsächlich kennt die „ihren“ Menschen viel besser als er selbst. Du triffst nicht immer objektive Entscheidungen und bewertest Situationen im Nachhinein sehr subjektiv. Das tut eine KI nicht. Deswegen kann sie Handlungen eigentlich besser beurteilen und objektivere Entscheidungen treffen – sofern sie auch wirklich alle Faktoren kennt.. Und genau da liegt auch die Gefahr.


Schreibe einen Kommentar